You Only Look Once: Unified, Real-Time Object Detection
Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
只需看過一次,便可以知道物件在影像當中的位置
比Fast R-CNN更少背景誤抓錯誤
問題
- R-CNN系列網路,需生成Bounding Box,再針對這些框的內容進行分類,兩階段的訓練會相當耗時且難以進行優化。
- Fast R-CNN: 因為沒有看到整張圖片,所以容易將背景誤認為物件。
方法
Grid Cell
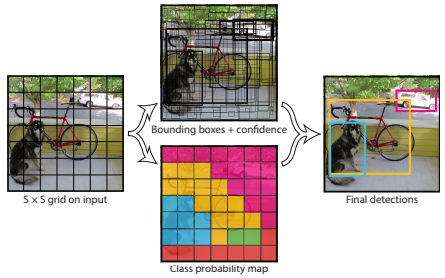
-
會將輸入影像切成S×S個格子(Grid),並分別輸出Bounding Boxes+confidence以及Class probability map。若有物件中心點落於該格子當中,則該格用於偵測該物件。
-
每格會預測B個Bounding Box以及物件信心值(若不存在物件則Pr(Object)為0)。
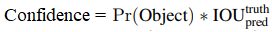
-
每個Bounding Box預測五個值: x , y , w , h , confidence。
- x , y 為物件在Grid cell中的中心點位置,0~1之間的值。
- w , h 為物件框長與寬並利用整張圖長寬進行歸一化到0~1之間。
- confidence: 預測框與真實框的IOU值。
-
另外每個Grid Cell會預測C類別的可能性(Class Probability map)

模型設計
- 啟發於GoogLeNet,利用1×1以及3×3卷積層取代GoogLeNet的Inception Module。
- 輸出為 7×7×30。
- 最後一層activation function為Leaky ReLU,並預測Class Probability以及Bounding Box座標。
Loss function
-
Sum-squared error,容易優化,但是因為影像中的Grid Cell沒有包含物件,因此會導致模型不穩使得訓練初期會有震盪。
-
增加了兩個參數分別用來調控grid cell有物件以及沒物件的狀況。
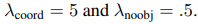
-
因為大物件與小物件的error代表意義不能夠一樣,因此會計算Bounding Box寬和高的平方根。
Final Loss Function:
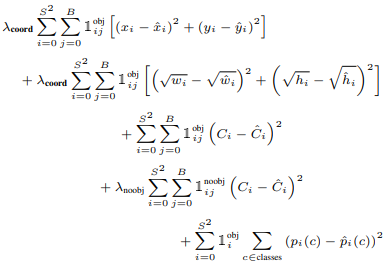
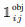 說明第i個Grid有物件,然後第j個最能代表該物件的類別預測(IOU最高者)。
說明第i個Grid有物件,然後第j個最能代表該物件的類別預測(IOU最高者)。
模型訓練
- 利用ImageNet 1000類競賽資料集進行預訓練。
- 並增加4個卷積層以及兩個全連接層,將輸入影像改成448×448大小。
超參數設定
- S(grid)=7
- B=2(每個grid輸出Bounding Boxes數量為2)
- C(Class Probability map)=20 (因為採用PASCAL VOC資料集,該資料集有20個類別)。
- Epochs=135
- Batch size=64
- Momentum and decay: 0.9 & 0.0005
- Learning Rate:
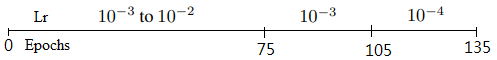
Limitation
- 一個Bounding Box只能有一個類別,無法解決有兩物件很靠近的狀況。
- 大物件與小物件的Bounding Box錯誤的懲罰接近,採用的平方根方法並沒有得到解決。
- 對於訓練集沒看過長寬比的Bounding Box,容易誤抓。
實驗結果
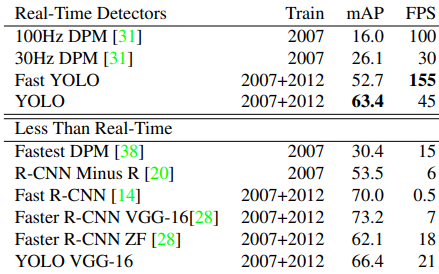
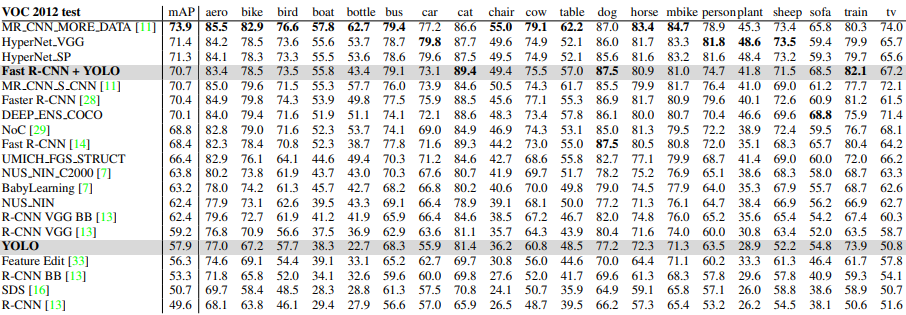
文章使用之圖片擷取自該篇論文

